The ETER data collection and management process is illustrated in Figure 1 below. It is organised around the ETER central database and data infrastructure, described in further detail in the ETER Handbook. The ETER central database stores all ETER variables and indicators based on ETER ID per year as a primary key (e.g. AT001.2015), i.e. all data and indicators are stored for each HEI and year.
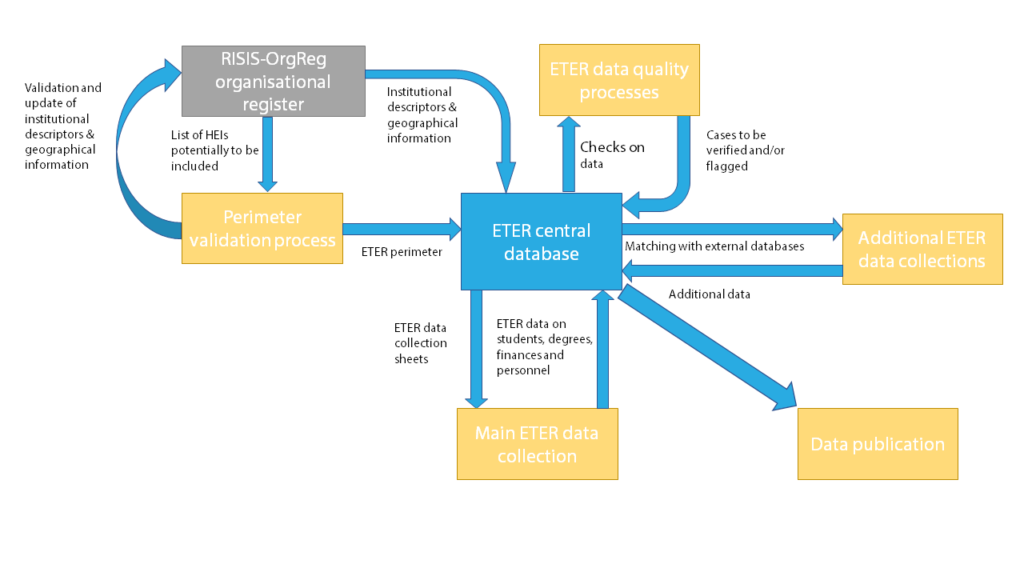
The main processes can be shortly described as follows:
- The goal of the perimeter validation process is to establish – for each year and country participating in ETER – the list of HEIs to be included in the database and any changes over time. It is based on the criteria described in chapter three and builds on the RISIS-OrgReg register of public research organisations. Alongside the perimeter validation, institutional descriptors and geographical information are updated in OrgReg and copied into ETER.
- The main ETER data collection process involves the collection and validation of data relating to students, degrees, finances, personnel and research activities, i.e. the core of the ETER dataset, from NSAs and national higher education ministries. Data collection is performed on a country-by-country basis in close cooperation between the ETER project team and country correspondents.
- Supplementary data collection involves integrating additional variables derived from existing databases at the European and international level, such as data concerning Erasmus mobility or quality assurance variables. It is performed directly by the ETER team in partnership with the source databases.
- When all data have been integrated into the ETER database and validated, data are made available through the public database interface.